Tuning Engines
Tuning Engines unifies, secures, and optimizes every AI interaction through one governed API with zero markup on infrastructure costs.
About Tuning Engines
Tuning Engines is a unified AI control and governance layer designed for teams building production intelligence across models, agents, tools, and fine-tuned systems. Developed by CerebrixOS, it functions as a Universal Intelligence Runtime that allows organizations to secure, govern, and optimize every AI interaction through a single platform. At its core, Tuning Engines brings together the full AI lifecycle in one governed environment, covering inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, AGT YAML policies, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. The product is built for developers who need OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, and coding-agent integrations, as well as for admins who require role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. A key differentiator is that infrastructure costs are passed through at-cost with zero markup, meaning organizations only pay for support and platform upkeep. Tuning Engines helps organizations move beyond isolated AI experiments into a secure, observable, cost-aware, and extensible AI operating layer where models can be trained, evaluated, routed, governed, and used by agents and tools at scale.
Features of Tuning Engines
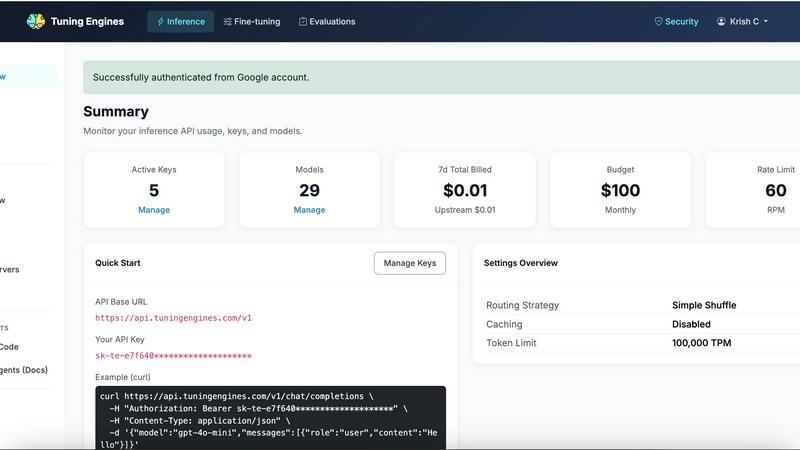
Unified Inference
Tuning Engines provides one OpenAI-compatible endpoint that works with open models, commercial frontier models, and your own tuned models. Developers can keep their existing SDK and simply swap one base URL to call any model with centralized policy, full auditability, and token controls applied to every request. This eliminates the need for code rewrites or learning new clients, supporting over 100 models behind a single interface with streaming and structured output capabilities.
Model Lifecycle Management
The platform supports the complete model lifecycle from build to tune to scale. In the build phase, developers hit one OpenAI-compatible endpoint and call any open or commercial model without GPU setup or cold starts. In the tune phase, teams can adapt open models to their data, language, and tasks using supervised fine-tuning, LoRA adapters, and evaluation gates. This ensures quality moves with business needs without managing GPU infrastructure.
Policy and Audit Controls
Tuning Engines offers centralized guardrails, access controls, and full request traceability across every model. Admins can implement role-based access, per-key budgets, rate limits, routing profiles, fallback rules, policy-as-code, credential sources, and auditability. Token economics are managed by design, with cost ceilings, quotas, routing, and fallbacks that keep spend and rate limits predictable across the entire organization.
Team and Tenant Management
The platform provides comprehensive team management capabilities including tenant isolation, billing controls, and usage analytics. Teams can connect multiple AI workflows through a single governed platform, supporting integrations with Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI coding environments. Admins can manage API keys, team roles, and billing across different departments or projects.
Use Cases of Tuning Engines
Code Assistance
Tuning Engines powers IDE copilots, code generation, refactoring, and debugging agents through its unified API. Development teams can build and deploy coding assistants that access multiple models through one endpoint, with centralized policy controls ensuring code quality and security. The platform supports popular coding-agent integrations and provides resource catalogs for models, agents, tools, and skills that developers can leverage.
Conversational AI
Organizations can build customer support bots, internal helpdesks, and multilingual chat systems using Tuning Engines. The platform enables teams to route conversations to the most appropriate model based on cost, quality, or latency requirements, with fallback policies ensuring continuous operation. Guardrails and policy controls maintain brand voice and compliance across all conversational interactions.
Agentic Systems
Tuning Engines supports multi-step reasoning, planning, and tool-using execution pipelines for building sophisticated AI agents. The platform provides MCP servers, reusable skills, and AGT YAML policies that enable agents to access tools and data sources securely. Runtime traces and usage analytics give teams visibility into agent behavior and performance across complex workflows.
Enterprise RAG
Organizations can implement secure, scalable retrieval over knowledge bases and private documents using Tuning Engines. The platform supports semantic search, enterprise assistants, and personalized recommendations with centralized policy controls for data access and compliance. Teams can fine-tune models on proprietary data and deploy them through the same unified endpoint used for other AI workloads.
Frequently Asked Questions
How does Tuning Engines handle pricing and infrastructure costs?
Tuning Engines passes through infrastructure costs at-cost with zero markup. Organizations only pay for support and platform upkeep, making it a cost-effective solution for production AI workloads. This pricing model is different by design, allowing teams to scale their AI operations without worrying about hidden margins or unexpected infrastructure fees.
What models are available through the Tuning Engines API?
The platform provides instant access to popular open weight models including Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and Embeddings from the BGE/E5 family. Additionally, commercial frontier models and any custom fine-tuned models are accessible through the same endpoint.
Can I use my existing OpenAI SDK with Tuning Engines?
Yes, Tuning Engines provides a drop-in OpenAI-compatible endpoint. You can keep your existing SDK and simply change the base URL to the Tuning Engines endpoint. This means no code rewrites, no new clients to learn, and immediate access to over 100 models with centralized policy, full auditability, and token controls applied to every request.
What integrations does Tuning Engines support for coding agents?
Tuning Engines supports connections with Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through a single governed platform. The platform provides CLI workflows, MCP access, and resource catalogs for models, agents, tools, and skills that integrate seamlessly with these development environments.
Similar to Tuning Engines
Distro
Distro is an AI Distribution Operator for B2B teams and agencies. It helps you publish content, find buyer conversations, engage high-intent prospects
Polymarket Trading Bot For Crypto
Polymarket Trading Bot For Crypto
HyperLake
HyperLake delivers a sovereign AI agent factory in your cloud with zero compute markup and governed access.
Minded
Minded empowers you to effortlessly train AI agents that manage tasks and enhance customer service, all in just minutes.
Klaws
Klaws is your 24/7 AI agent that learns, remembers, and executes tasks seamlessly while you sleep, transforming work efficiency.
Playwriter
Playwriter lets AI agents control your actual Chrome browser with all your logins and extensions intact.
Patrivox
Patrivox uses AI to instantly digitize, search, and uncover connections within your document archives.
Stable Commerce
Launch your online store in under 2 minutes with AI that automates setup, optimization, and everything in between.