Agenta vs qtrl.ai
Side-by-side comparison to help you choose the right AI tool.
Agenta is the open-source platform for teams to collaboratively build and manage reliable LLM applications.
Last updated: March 1, 2026
qtrl.ai
qtrl.ai scales QA with AI agents while ensuring full team control and governance.
Last updated: March 4, 2026
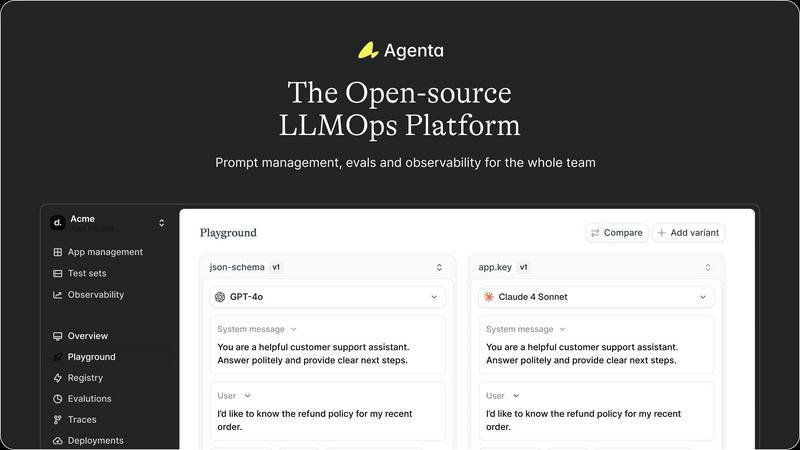
Visual Comparison
Agenta
qtrl.ai
Feature Comparison
Agenta
Unified Playground & Versioning
Agenta provides a centralized playground where teams can experiment with and compare different prompts and models side-by-side in real-time. Every change is automatically versioned, creating a complete audit trail. This eliminates the chaos of managing prompts across disparate documents and ensures that every iteration is tracked, reproducible, and can be easily reverted or analyzed, providing a solid foundation for collaborative development.
Comprehensive Evaluation Suite
The platform replaces guesswork with evidence through a robust evaluation framework. Teams can create systematic processes to validate changes using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta allows evaluation of full agentic traces, testing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation, enabling domain experts to provide qualitative feedback directly within the workflow.
Production Observability & Debugging
Agenta offers deep observability by tracing every LLM request in production. When errors occur, teams can pinpoint the exact failure point in complex chains or agentic workflows. Traces can be annotated collaboratively and, with a single click, turned into test cases to close the feedback loop. This transforms debugging from a speculative exercise into a precise, data-driven process and helps monitor performance for regressions.
Collaborative, Model-Agnostic Infrastructure
Designed for cross-functional teams, Agenta breaks down silos between developers, PMs, and experts. It provides full parity between its UI and API, integrating programmatic and visual workflows into one hub. The platform is model-agnostic, supporting any provider (OpenAI, Anthropic, etc.) and framework (LangChain, LlamaIndex), preventing vendor lock-in and allowing teams to freely use the best model for each task.
qtrl.ai
Enterprise-Grade Test Management
qtrl provides a robust, centralized hub for all QA artifacts. It enables teams to create, organize, and manage test cases, plans, and runs with full traceability back to requirements. This ensures clear audit trails, supports compliance needs, and offers a single source of truth for both manual and automated testing workflows, giving managers complete oversight and control over the quality process.
Autonomous QA Agents
This core feature introduces intelligent automation through AI agents that execute high-level instructions in real browsers. Teams can describe a test in plain English, and the agent performs the actions across defined environments. These agents operate at scale, run continuously or on-demand, and function within strict governance rules, providing automation power without the fragility of traditional script maintenance.
Progressive Automation & Adaptive Memory
qtrl champions a step-by-step journey to automation. Teams begin with human-written instructions, then progress to AI-generated tests, with full review capabilities at each stage. The platform's Adaptive Memory builds a living knowledge base of your application, learning from every interaction and execution to power smarter, more context-aware test suggestions and maintenance over time.
Multi-Environment Execution & Governance
The platform supports secure testing across development, staging, and production environments. It manages per-environment variables and encrypted secrets, ensuring sensitive data is never exposed to AI agents. Built-in governance features like permissioned autonomy levels, full agent visibility, and transparent decision-making ensure enterprise-ready security and foster trust in the automated processes.
Use Cases
Agenta
Streamlining Cross-Functional AI Product Development
For teams building customer-facing LLM applications, Agenta unites developers, product managers, and subject matter experts on a single platform. PMs can define test sets and success criteria, experts can refine prompts and provide human feedback via the UI, and developers can implement complex agentic logic—all while maintaining a shared version history and evidence base for every decision, dramatically speeding up the iteration cycle.
Implementing Rigorous LLM Evaluation & Benchmarking
Organizations needing to systematically improve AI quality use Agenta to establish a rigorous evaluation pipeline. Teams can run automated A/B tests between prompt versions or model providers, evaluate performance on curated test sets, and combine automated scores with human ratings. This is critical for applications where reliability, safety, or factual accuracy are paramount, ensuring every deployment is backed by data.
Debugging Complex Agentic Systems in Production
When a multi-step AI agent fails in production, traditional logging is insufficient. Agenta's trace observability allows engineers to replay the exact sequence of LLM calls, tool executions, and reasoning steps that led to an error. By saving faulty traces as test cases and experimenting with fixes in the playground, teams can quickly diagnose root causes and deploy validated solutions, reducing mean time to resolution.
Centralizing Prompt Management & Governance
Companies struggling with "prompt sprawl" across Slack, Google Docs, and code repositories use Agenta as their system of record. It centralizes all prompts, their versions, associated evaluations, and performance data. This governance model ensures compliance, enables knowledge sharing, and provides visibility into which prompts are deployed where, turning a management headache into a structured asset.
qtrl.ai
Scaling Beyond Manual Testing
For QA teams overwhelmed by repetitive manual test cycles, qtrl offers a graceful off-ramp. Teams can start by structuring their existing manual cases in the platform and then progressively introduce automation for the most tedious flows using autonomous agents, dramatically increasing test coverage and execution speed without a steep learning curve or loss of control.
Modernizing Legacy QA Workflows
Companies stuck with outdated, siloed, or script-heavy automation frameworks can use qtrl to consolidate and modernize. The platform integrates test management and execution, reduces maintenance burden via AI, and provides the dashboards and traceability missing from legacy setups, enabling a cohesive, data-driven quality strategy.
Ensuring Governance in Enterprise AI Adoption
Enterprises that require strict compliance, audit trails, and security for any AI tool find a safe partner in qtrl. Its "governance by design" philosophy, with features like permissioned autonomy, full visibility into agent actions, and encrypted secret management, allows large organizations to harness AI's power for QA without compromising on oversight or regulatory requirements.
Accelerating Product-Led Engineering Teams
Fast-moving product and engineering teams need to ensure quality without slowing down deployment. qtrl fits seamlessly into CI/CD pipelines, provides continuous quality feedback, and allows developers to create and run tests via simple instructions, enabling rapid iteration with confidence and shifting quality left in the development process.
Overview
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental chaos of modern LLM application development. It acts as a centralized command center for AI teams, bridging the critical gap between rapid experimentation and reliable production deployment. The platform is built for collaborative teams comprising developers, product managers, and subject matter experts who are tired of scattered prompts in Slack, siloed workflows, and the perilous "vibe testing" of changes before shipping. From a developer's perspective, Agenta provides the integrated tooling necessary to implement LLMOps best practices, enabling systematic experimentation with prompts and models, automated evaluations, and deep production observability. For product managers and domain experts, it offers a unified, accessible UI to participate directly in the AI development lifecycle—editing prompts, running evaluations, and providing feedback without writing code. Its core value proposition is transforming unpredictability into a structured, evidence-based process. By offering a single source of truth for the entire LLM lifecycle, Agenta empowers organizations to build, evaluate, debug, and ship AI applications with confidence, moving decisively from guesswork to governance and accelerating the journey from prototype to production.
About qtrl.ai
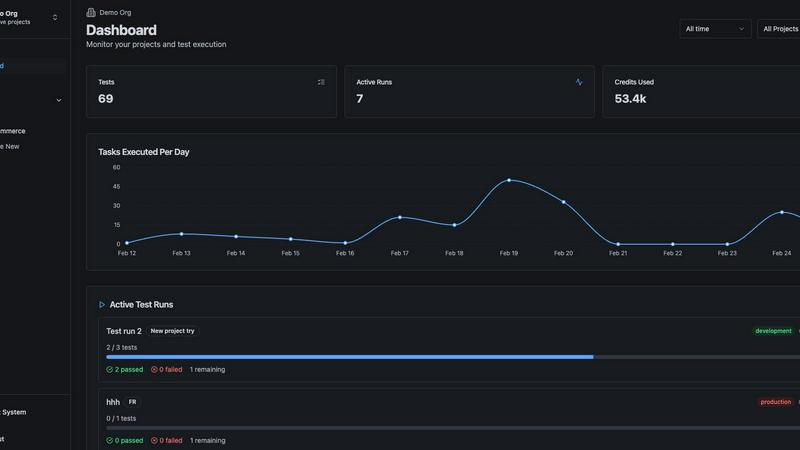
qtrl.ai is a modern, progressive QA platform engineered to solve the fundamental tension in software quality assurance: the need for both speed and control. It is not merely another test automation tool, but a unified platform that seamlessly integrates enterprise-grade test management with powerful, trustworthy AI automation. At its heart, qtrl provides a centralized command center for all quality activities. Teams can meticulously organize test cases, plan and execute test runs, trace requirements to ensure comprehensive coverage, and monitor quality health through real-time dashboards. This structured foundation offers engineering leads and QA managers unparalleled visibility into testing status, risk areas, and release readiness.
Where qtrl truly distinguishes itself is through its philosophy of "progressive automation." Rejecting the risky, all-or-nothing approach of "black-box" AI, qtrl allows teams to start with familiar, manual test management. When ready, they can incrementally leverage intelligent autonomous agents. These agents can generate robust UI tests from simple English instructions, autonomously maintain them against application changes, and execute them at scale across multiple browsers and environments. This makes qtrl an ideal solution for product-led engineering teams seeking velocity, QA groups transitioning from manual processes, organizations modernizing legacy workflows, and enterprises that demand strict compliance, audit trails, and governance. Ultimately, qtrl bridges the gap between the slow pace of manual testing and the brittle, expensive complexity of traditional scripted automation, offering a trusted, scalable path to intelligent quality assurance.
Frequently Asked Questions
Agenta FAQ
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, where developers can review the code, contribute to the project, and self-host the entire platform. This open model ensures transparency, avoids vendor lock-in, and allows the tool to be customized to fit specific organizational needs and integrated deeply into existing infrastructure.
How does Agenta handle collaboration for non-technical team members?
Agenta is specifically designed with a strong UI layer for non-technical participants. Product managers and domain experts can access the playground to safely edit and experiment with prompts without touching code. They can also view evaluation results, compare experiments, and provide human feedback or annotations directly through the web interface, making the AI development process truly collaborative.
Can I use Agenta with any LLM provider or framework?
Absolutely. Agenta is model-agnostic and framework-agnostic. It seamlessly integrates with major providers like OpenAI, Anthropic, Cohere, and open-source models via Ollama or Replicate. It also works with popular development frameworks such as LangChain and LlamaIndex. This flexibility allows teams to choose the best tools for their task and switch providers without overhauling their entire operations platform.
What is the difference between Agenta's evaluation and simple unit testing?
While unit tests check code logic, Agenta's evaluation assesses the probabilistic output of LLMs. It allows you to evaluate the full reasoning trace of an agent, not just the final string output. You can employ LLM-as-a-judge evaluators, custom code checks, and human scoring in a unified workflow. This creates a holistic, systematic process to measure the quality, reliability, and correctness of AI behavior against real-world scenarios.
qtrl.ai FAQ
How does qtrl.ai's AI differ from other "autonomous" testing tools?
qtrl.ai rejects the "black-box" AI-first approach that can be unpredictable and risky. Instead, it employs a progressive, trust-earning model. The AI operates as assistive agents that execute clear instructions or generate tests that are always reviewable and editable by humans. Governance controls, full transparency into agent actions, and a focus on augmenting (not replacing) human oversight make its AI practical and trustworthy for real enterprise workflows.
Can we use qtrl.ai if we currently only do manual testing?
Absolutely. qtrl is explicitly designed for this scenario. You can begin by using it as a powerful test management system to organize your existing manual cases and plans. When you're ready, you can start automating specific tests using plain English instructions with the AI agents, allowing you to scale your efforts incrementally without a disruptive, all-at-once transition.
How does qtrl handle testing across different environments and with sensitive data?
qtrl provides secure, multi-environment execution capabilities. You can define various environments (dev, staging, prod) with their own variables. Crucially, sensitive data like passwords and API keys can be stored as encrypted secrets that are injected at runtime. These secrets are never exposed to the AI agents, ensuring security and compliance are maintained throughout the testing process.
What kind of integration and traceability does qtrl support?
qtrl is built for real-world workflows. It supports requirements management integration, allowing you to trace tests back to specific features or user stories for coverage analysis. It also offers CI/CD pipeline support for automated test execution as part of your build process. Furthermore, its centralized nature provides inherent traceability from test cases to execution results and defects, all visible in comprehensive dashboards.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to bring order and collaboration to the development of large language model applications. It serves as a centralized hub for teams to experiment, evaluate, and deploy AI features systematically, moving beyond ad-hoc prompt management and unreliable testing. Users explore alternatives for various reasons. Some require a fully managed, proprietary solution with dedicated support, while others might seek a platform with a narrower focus, such as only production monitoring or only prompt management. Budget, team size, and the need for specific integrations or deployment models also drive the search for different tools. When evaluating an alternative, consider your team's primary pain points. Key factors include the platform's approach to collaborative experimentation, the depth of its evaluation and testing framework, its observability and debugging capabilities for production systems, and whether its licensing and deployment model aligns with your technical and financial constraints.
qtrl.ai Alternatives
qtrl.ai is a modern QA platform in the automation and dev tools space. It uniquely blends enterprise-grade test management with a progressive, trustworthy AI layer, allowing teams to scale their testing efforts while maintaining full control and governance over the process. Users often explore alternatives for various reasons. These can include budget constraints, the need for a different feature mix, or specific platform requirements like deeper integrations with an existing toolchain. Some teams may also seek a solution that is either purely manual, fully open-source, or takes a more aggressive, AI-first approach to automation. When evaluating alternatives, consider your team's primary goals. Key factors include the balance between structured test management and automation capabilities, the level of AI integration and transparency desired, and the importance of enterprise features like audit trails and compliance. The ideal choice should align with your team's maturity, from manual testing to advanced autonomous agents.