Agenta
Agenta is the open-source platform for teams to collaboratively build and manage reliable LLM applications.
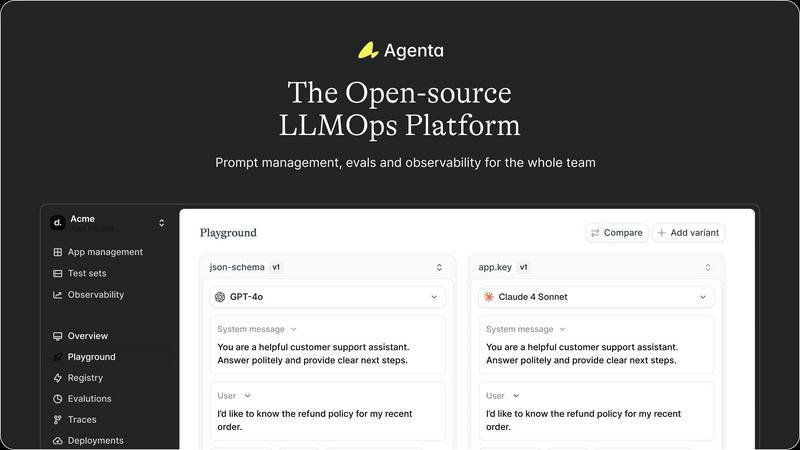
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental chaos of modern LLM application development. It acts as a centralized command center for AI teams, bridging the critical gap between rapid experimentation and reliable production deployment. The platform is built for collaborative teams comprising developers, product managers, and subject matter experts who are tired of scattered prompts in Slack, siloed workflows, and the perilous "vibe testing" of changes before shipping. From a developer's perspective, Agenta provides the integrated tooling necessary to implement LLMOps best practices, enabling systematic experimentation with prompts and models, automated evaluations, and deep production observability. For product managers and domain experts, it offers a unified, accessible UI to participate directly in the AI development lifecycle—editing prompts, running evaluations, and providing feedback without writing code. Its core value proposition is transforming unpredictability into a structured, evidence-based process. By offering a single source of truth for the entire LLM lifecycle, Agenta empowers organizations to build, evaluate, debug, and ship AI applications with confidence, moving decisively from guesswork to governance and accelerating the journey from prototype to production.
Features of Agenta
Unified Playground & Versioning
Agenta provides a centralized playground where teams can experiment with and compare different prompts and models side-by-side in real-time. Every change is automatically versioned, creating a complete audit trail. This eliminates the chaos of managing prompts across disparate documents and ensures that every iteration is tracked, reproducible, and can be easily reverted or analyzed, providing a solid foundation for collaborative development.
Comprehensive Evaluation Suite
The platform replaces guesswork with evidence through a robust evaluation framework. Teams can create systematic processes to validate changes using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta allows evaluation of full agentic traces, testing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation, enabling domain experts to provide qualitative feedback directly within the workflow.
Production Observability & Debugging
Agenta offers deep observability by tracing every LLM request in production. When errors occur, teams can pinpoint the exact failure point in complex chains or agentic workflows. Traces can be annotated collaboratively and, with a single click, turned into test cases to close the feedback loop. This transforms debugging from a speculative exercise into a precise, data-driven process and helps monitor performance for regressions.
Collaborative, Model-Agnostic Infrastructure
Designed for cross-functional teams, Agenta breaks down silos between developers, PMs, and experts. It provides full parity between its UI and API, integrating programmatic and visual workflows into one hub. The platform is model-agnostic, supporting any provider (OpenAI, Anthropic, etc.) and framework (LangChain, LlamaIndex), preventing vendor lock-in and allowing teams to freely use the best model for each task.
Use Cases of Agenta
Streamlining Cross-Functional AI Product Development
For teams building customer-facing LLM applications, Agenta unites developers, product managers, and subject matter experts on a single platform. PMs can define test sets and success criteria, experts can refine prompts and provide human feedback via the UI, and developers can implement complex agentic logic—all while maintaining a shared version history and evidence base for every decision, dramatically speeding up the iteration cycle.
Implementing Rigorous LLM Evaluation & Benchmarking
Organizations needing to systematically improve AI quality use Agenta to establish a rigorous evaluation pipeline. Teams can run automated A/B tests between prompt versions or model providers, evaluate performance on curated test sets, and combine automated scores with human ratings. This is critical for applications where reliability, safety, or factual accuracy are paramount, ensuring every deployment is backed by data.
Debugging Complex Agentic Systems in Production
When a multi-step AI agent fails in production, traditional logging is insufficient. Agenta's trace observability allows engineers to replay the exact sequence of LLM calls, tool executions, and reasoning steps that led to an error. By saving faulty traces as test cases and experimenting with fixes in the playground, teams can quickly diagnose root causes and deploy validated solutions, reducing mean time to resolution.
Centralizing Prompt Management & Governance
Companies struggling with "prompt sprawl" across Slack, Google Docs, and code repositories use Agenta as their system of record. It centralizes all prompts, their versions, associated evaluations, and performance data. This governance model ensures compliance, enables knowledge sharing, and provides visibility into which prompts are deployed where, turning a management headache into a structured asset.
Frequently Asked Questions
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, where developers can review the code, contribute to the project, and self-host the entire platform. This open model ensures transparency, avoids vendor lock-in, and allows the tool to be customized to fit specific organizational needs and integrated deeply into existing infrastructure.
How does Agenta handle collaboration for non-technical team members?
Agenta is specifically designed with a strong UI layer for non-technical participants. Product managers and domain experts can access the playground to safely edit and experiment with prompts without touching code. They can also view evaluation results, compare experiments, and provide human feedback or annotations directly through the web interface, making the AI development process truly collaborative.
Can I use Agenta with any LLM provider or framework?
Absolutely. Agenta is model-agnostic and framework-agnostic. It seamlessly integrates with major providers like OpenAI, Anthropic, Cohere, and open-source models via Ollama or Replicate. It also works with popular development frameworks such as LangChain and LlamaIndex. This flexibility allows teams to choose the best tools for their task and switch providers without overhauling their entire operations platform.
What is the difference between Agenta's evaluation and simple unit testing?
While unit tests check code logic, Agenta's evaluation assesses the probabilistic output of LLMs. It allows you to evaluate the full reasoning trace of an agent, not just the final string output. You can employ LLM-as-a-judge evaluators, custom code checks, and human scoring in a unified workflow. This creates a holistic, systematic process to measure the quality, reliability, and correctness of AI behavior against real-world scenarios.
Explore more in this category:
Similar to Agenta
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.
JavaScript Tools
Formatters for JSON, HTML, CSS, XML, and Markdown
Headless Domains
Headless Domains gives AI agents portable, verifiable identities to prove trust, permissions, and payments across any platform.
ProcessSpy
ProcessSpy is a powerful process monitor for Mac that delivers in-depth insights and advanced filtering for optimal performance tracking.