Agenta vs Fallom
Side-by-side comparison to help you choose the right AI tool.
Agenta is the open-source platform for teams to collaboratively build and manage reliable LLM applications.
Last updated: March 1, 2026
Fallom provides real-time observability for AI agents, ensuring complete visibility and cost transparency into LLM.
Last updated: February 28, 2026
Visual Comparison
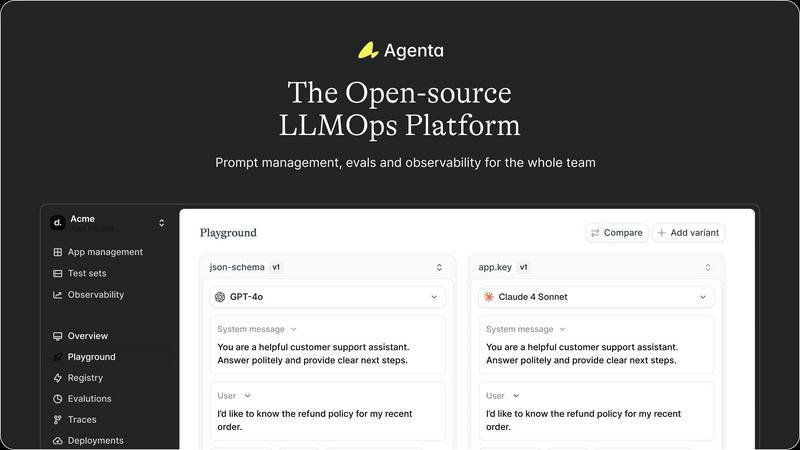
Agenta
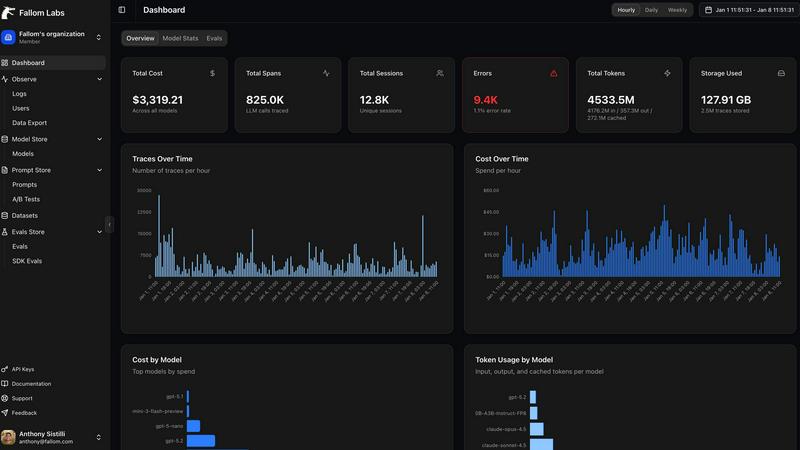
Fallom
Feature Comparison
Agenta
Unified Playground & Versioning
Agenta provides a centralized playground where teams can experiment with and compare different prompts and models side-by-side in real-time. Every change is automatically versioned, creating a complete audit trail. This eliminates the chaos of managing prompts across disparate documents and ensures that every iteration is tracked, reproducible, and can be easily reverted or analyzed, providing a solid foundation for collaborative development.
Comprehensive Evaluation Suite
The platform replaces guesswork with evidence through a robust evaluation framework. Teams can create systematic processes to validate changes using LLM-as-a-judge, custom code evaluators, or built-in metrics. Crucially, Agenta allows evaluation of full agentic traces, testing each intermediate reasoning step, not just the final output. It also seamlessly integrates human evaluation, enabling domain experts to provide qualitative feedback directly within the workflow.
Production Observability & Debugging
Agenta offers deep observability by tracing every LLM request in production. When errors occur, teams can pinpoint the exact failure point in complex chains or agentic workflows. Traces can be annotated collaboratively and, with a single click, turned into test cases to close the feedback loop. This transforms debugging from a speculative exercise into a precise, data-driven process and helps monitor performance for regressions.
Collaborative, Model-Agnostic Infrastructure
Designed for cross-functional teams, Agenta breaks down silos between developers, PMs, and experts. It provides full parity between its UI and API, integrating programmatic and visual workflows into one hub. The platform is model-agnostic, supporting any provider (OpenAI, Anthropic, etc.) and framework (LangChain, LlamaIndex), preventing vendor lock-in and allowing teams to freely use the best model for each task.
Fallom
End-to-End Tracing
Fallom's end-to-end tracing feature enables teams to monitor every LLM call comprehensively. This includes tracking prompts, outputs, and tool function calls, allowing users to gain a complete understanding of LLM interactions and performance metrics.
Real-Time Observability
With real-time observability, Fallom provides live tracking of AI agent activities, enabling users to analyze timing, debug issues, and monitor tool calls instantly. This empowers teams to act quickly and effectively when anomalies arise.
Cost Attribution
Fallom's cost attribution feature allows organizations to track spending on LLMs by model, user, or team. This transparency aids in budgeting and chargeback processes, ensuring that costs are allocated accurately and efficiently.
Compliance Ready
Built with compliance in mind, Fallom offers comprehensive audit trails, input/output logging, and user consent tracking. This functionality ensures that organizations can meet regulatory requirements such as the EU AI Act and GDPR, making Fallom a reliable choice for regulated industries.
Use Cases
Agenta
Streamlining Cross-Functional AI Product Development
For teams building customer-facing LLM applications, Agenta unites developers, product managers, and subject matter experts on a single platform. PMs can define test sets and success criteria, experts can refine prompts and provide human feedback via the UI, and developers can implement complex agentic logic—all while maintaining a shared version history and evidence base for every decision, dramatically speeding up the iteration cycle.
Implementing Rigorous LLM Evaluation & Benchmarking
Organizations needing to systematically improve AI quality use Agenta to establish a rigorous evaluation pipeline. Teams can run automated A/B tests between prompt versions or model providers, evaluate performance on curated test sets, and combine automated scores with human ratings. This is critical for applications where reliability, safety, or factual accuracy are paramount, ensuring every deployment is backed by data.
Debugging Complex Agentic Systems in Production
When a multi-step AI agent fails in production, traditional logging is insufficient. Agenta's trace observability allows engineers to replay the exact sequence of LLM calls, tool executions, and reasoning steps that led to an error. By saving faulty traces as test cases and experimenting with fixes in the playground, teams can quickly diagnose root causes and deploy validated solutions, reducing mean time to resolution.
Centralizing Prompt Management & Governance
Companies struggling with "prompt sprawl" across Slack, Google Docs, and code repositories use Agenta as their system of record. It centralizes all prompts, their versions, associated evaluations, and performance data. This governance model ensures compliance, enables knowledge sharing, and provides visibility into which prompts are deployed where, turning a management headache into a structured asset.
Fallom
Debugging AI Systems
Fallom is invaluable for teams debugging AI systems, as it provides granular insights into LLM calls and tool interactions. This allows engineers to identify and resolve issues quickly, ensuring the reliability of AI features in production.
Performance Optimization
Organizations can use Fallom to analyze performance metrics and identify bottlenecks in their AI workflows. By understanding latency and cost per call, teams can make informed decisions to optimize their AI operations for better efficiency.
Compliance Management
For businesses operating in regulated environments, Fallom assists in maintaining compliance with legal requirements. Its audit trails and consent tracking features help organizations navigate complex regulations with confidence.
Session Tracking and Analytics
Fallom enables teams to track sessions and user interactions, providing valuable insights into usage patterns and power users. This data helps organizations to tailor their AI offerings and improve user experiences effectively.
Overview
About Agenta
Agenta is an open-source LLMOps platform engineered to solve the fundamental chaos of modern LLM application development. It acts as a centralized command center for AI teams, bridging the critical gap between rapid experimentation and reliable production deployment. The platform is built for collaborative teams comprising developers, product managers, and subject matter experts who are tired of scattered prompts in Slack, siloed workflows, and the perilous "vibe testing" of changes before shipping. From a developer's perspective, Agenta provides the integrated tooling necessary to implement LLMOps best practices, enabling systematic experimentation with prompts and models, automated evaluations, and deep production observability. For product managers and domain experts, it offers a unified, accessible UI to participate directly in the AI development lifecycle—editing prompts, running evaluations, and providing feedback without writing code. Its core value proposition is transforming unpredictability into a structured, evidence-based process. By offering a single source of truth for the entire LLM lifecycle, Agenta empowers organizations to build, evaluate, debug, and ship AI applications with confidence, moving decisively from guesswork to governance and accelerating the journey from prototype to production.
About Fallom
Fallom is an innovative AI-native observability platform tailored for the dynamic and complex landscape of Large Language Model (LLM) and AI agent applications. Designed to provide critical visibility, Fallom empowers engineering and product teams to operate AI-driven features reliably and efficiently in production environments. By delivering comprehensive end-to-end tracing for every LLM call, Fallom captures essential data such as prompts, outputs, tool and function calls, token usage, latency, and cost per call. This granular visibility is crucial for organizations striving to demystify AI systems, moving away from the traditional "black box" approach. Built on the open standard OpenTelemetry, Fallom ensures vendor neutrality and seamless integration, allowing teams to work with leading model providers such as OpenAI, Anthropic, and Google. With actionable insights structured from telemetry data, Fallom offers features like session-level context, timing waterfalls for multi-step workflows, and enterprise-grade compliance tools. These capabilities not only support adherence to regulations like the EU AI Act and GDPR but also enable organizations to debug issues promptly, optimize performance and costs, and confidently scale their AI initiatives.
Frequently Asked Questions
Agenta FAQ
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, where developers can review the code, contribute to the project, and self-host the entire platform. This open model ensures transparency, avoids vendor lock-in, and allows the tool to be customized to fit specific organizational needs and integrated deeply into existing infrastructure.
How does Agenta handle collaboration for non-technical team members?
Agenta is specifically designed with a strong UI layer for non-technical participants. Product managers and domain experts can access the playground to safely edit and experiment with prompts without touching code. They can also view evaluation results, compare experiments, and provide human feedback or annotations directly through the web interface, making the AI development process truly collaborative.
Can I use Agenta with any LLM provider or framework?
Absolutely. Agenta is model-agnostic and framework-agnostic. It seamlessly integrates with major providers like OpenAI, Anthropic, Cohere, and open-source models via Ollama or Replicate. It also works with popular development frameworks such as LangChain and LlamaIndex. This flexibility allows teams to choose the best tools for their task and switch providers without overhauling their entire operations platform.
What is the difference between Agenta's evaluation and simple unit testing?
While unit tests check code logic, Agenta's evaluation assesses the probabilistic output of LLMs. It allows you to evaluate the full reasoning trace of an agent, not just the final string output. You can employ LLM-as-a-judge evaluators, custom code checks, and human scoring in a unified workflow. This creates a holistic, systematic process to measure the quality, reliability, and correctness of AI behavior against real-world scenarios.
Fallom FAQ
What makes Fallom different from other observability tools?
Fallom is specifically designed for LLM and AI agent applications, providing tailored insights and observability that general-purpose tools do not offer. Its focus on AI workflows ensures that users gain relevant and actionable data.
How does Fallom ensure compliance with regulations?
Fallom includes features such as comprehensive audit trails, input/output logging, and user consent tracking, which are essential for meeting regulatory requirements like the EU AI Act and GDPR.
Can Fallom work with multiple AI model providers?
Yes, Fallom is built on the open standard OpenTelemetry, allowing it to integrate seamlessly with any major model provider, ensuring vendor neutrality and flexibility for users.
How quickly can teams start using Fallom?
Fallom is designed for quick setup, with an estimated setup time of under five minutes. This enables teams to start tracing their AI agents and gaining insights without extensive preparation or delays.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to bring order and collaboration to the development of large language model applications. It serves as a centralized hub for teams to experiment, evaluate, and deploy AI features systematically, moving beyond ad-hoc prompt management and unreliable testing. Users explore alternatives for various reasons. Some require a fully managed, proprietary solution with dedicated support, while others might seek a platform with a narrower focus, such as only production monitoring or only prompt management. Budget, team size, and the need for specific integrations or deployment models also drive the search for different tools. When evaluating an alternative, consider your team's primary pain points. Key factors include the platform's approach to collaborative experimentation, the depth of its evaluation and testing framework, its observability and debugging capabilities for production systems, and whether its licensing and deployment model aligns with your technical and financial constraints.
Fallom Alternatives
Fallom is an AI-native observability platform that provides critical visibility into Large Language Model (LLM) and AI agent applications. As teams work to integrate AI technologies into their products, they often seek alternatives due to various reasons, including pricing, feature sets, and specific platform needs. Users may find that existing solutions do not fully meet their requirements for compliance, scalability, or ease of integration, prompting them to explore other options in the market. When searching for an alternative, it is essential to consider factors such as end-to-end visibility, compliance capabilities, and the ability to integrate with multiple model providers. A solution that offers detailed tracing, actionable insights, and enterprise-ready features can significantly enhance the performance and reliability of AI-powered applications. Additionally, vendor neutrality and the flexibility to adapt to evolving needs should be high on the list of priorities.