LLMWise vs WebPageSnap - Professional Web Scraper API
Side-by-side comparison to help you choose the right AI tool.
LLMWise offers a single API to seamlessly access and compare multiple AI models, charging only for what you use.
Last updated: February 28, 2026
WebPageSnap is a lightning-fast API that scrapes and delivers structured data from any webpage in under 50 milliseconds.
Last updated: February 28, 2026
Visual Comparison
LLMWise
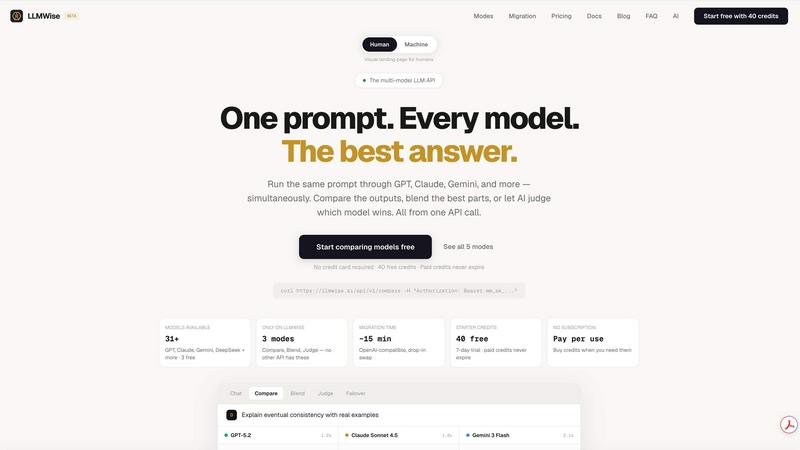
WebPageSnap - Professional Web Scraper API
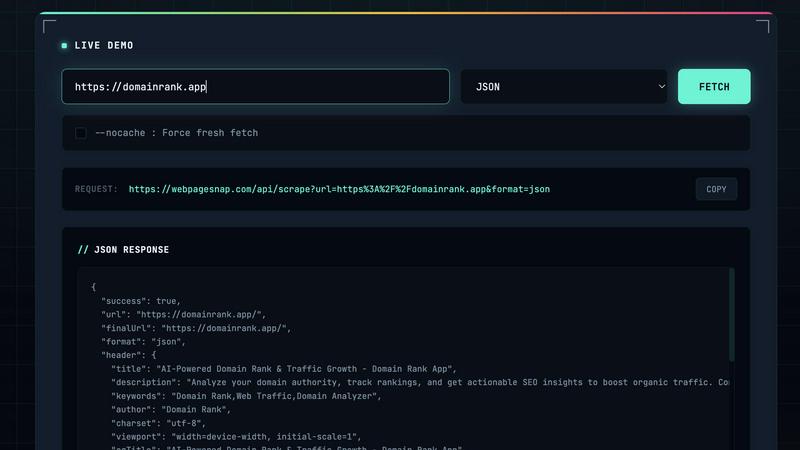
Feature Comparison
LLMWise
Smart Routing
LLMWise employs advanced smart routing to ensure that every prompt is directed to the most appropriate model. For instance, coding queries can be sent to GPT, while creative tasks are routed to Claude, and translations are handled by Gemini. This feature maximizes efficiency and output quality by leveraging the strengths of each model.
Compare & Blend
The compare and blend feature allows users to run prompts across different models side-by-side, enabling direct comparison of responses. Users can blend outputs from multiple models into a single, cohesive answer, enhancing the overall quality of the results. Additionally, the Judge mode evaluates outputs to determine which model provides the best response.
Resilient Failover
LLMWise is built with resilience in mind, featuring a circuit-breaker failover system that automatically reroutes requests to backup models if a primary provider experiences downtime. This ensures that applications remain operational and reliable, protecting users against interruptions.
Test & Optimize
Developers can utilize LLMWise's comprehensive benchmarking suites and batch tests to optimize performance based on speed, cost, or reliability. Automated regression checks are also included to ensure that updates do not introduce new issues, enabling continuous improvement of AI integrations.
WebPageSnap - Professional Web Scraper API
Smart Cache with KV Storage
This feature implements an intelligent caching layer using Cloudflare's KV storage, dramatically reducing latency and load on target websites. With a configurable 7-day Time-To-Live (TTL) and an impressive 95%+ cache hit rate, frequently requested pages are served from the nearest edge node in milliseconds. This not only accelerates your data pipelines but also promotes respectful web scraping etiquette by minimizing redundant requests. The optional nocache parameter provides full control, allowing you to bypass the cache for scenarios requiring absolutely fresh data.
Global Edge Network Deployment
Performance is geographically distributed with WebPageSnap's deployment across 200+ global edge nodes. This architecture ensures that API requests are processed from a location nearest to the origin, slashing latency and providing consistent, sub-50ms response times worldwide. For businesses operating internationally or scraping region-specific content, this feature guarantees that data retrieval speed is never compromised by physical distance, enabling real-time data processing and analysis on a global scale.
Multi-Format Output (JSON & HTML)
Flexibility in data handling is provided through support for multiple output formats. Users can request raw HTML for full-page rendering or custom parsing, or opt for structured JSON. The JSON format is particularly powerful, as it includes pre-extracted, normalized metadata such as page titles, descriptions, Open Graph tags, and Twitter Card data within the header object, alongside the full HTML body. This eliminates the need for initial parsing and allows for immediate integration into applications and databases.
Anti-Bot Bypass with Realistic Simulation
Modern websites employ sophisticated anti-bot measures. WebPageSnap counters this with advanced browser simulation that mimics real user behavior, including the automatic handling of JavaScript redirects to reach the final page content. This "Smart Redirect" capability ensures successful data extraction from dynamic, JavaScript-heavy single-page applications (SPAs) and complex websites that would otherwise thwart simpler HTTP client-based scrapers.
Use Cases
LLMWise
Application Development
LLMWise is ideal for application developers who require various AI functionalities without managing multiple subscriptions. By leveraging a single API, developers can integrate diverse LLM capabilities into their applications, enhancing user experiences with tailored responses.
Content Creation
For content creators, LLMWise offers a powerful tool to generate high-quality written material. Whether writing blogs, social media posts, or marketing copy, users can utilize different models to refine their content, ensuring creativity and accuracy.
Translation Services
Businesses that require translation services can benefit from LLMWise's intelligent routing to the best translation models. This feature ensures that translations are not only accurate but also contextually appropriate, enhancing communication across languages.
Research and Analysis
Researchers can utilize LLMWise to gather insights and synthesize information from multiple models. The ability to compare and blend responses allows for a more comprehensive analysis, leading to better-informed conclusions and recommendations.
WebPageSnap - Professional Web Scraper API
Competitive Intelligence and Market Research
Businesses can automate the monitoring of competitors' websites to track product changes, pricing updates, promotional campaigns, and content strategies. By scheduling regular scrapes, companies gain a timely, data-driven understanding of market movements, allowing them to adjust their own strategies proactively and maintain a competitive edge without manual, time-consuming research.
Data Aggregation for Machine Learning
Data scientists and AI researchers require large, clean, and structured datasets for training models. WebPageSnap facilitates the efficient collection of text, metadata, and content from diverse public sources across the web. This automated aggregation is crucial for projects in natural language processing, sentiment analysis, and trend forecasting, providing the foundational data layer for advanced analytics.
Content Syndication and News Monitoring
Media companies and content curators can use the API to pull in articles, blog posts, or news snippets from a wide array of publishers. The ability to extract clean HTML and key metadata (title, author, description, image) allows for the quick creation of news digests, content hubs, or personalized news feeds that enrich a platform's offerings with relevant, external content.
SEO and Digital Marketing Analysis
SEO professionals and marketers can programmatically audit and analyze website structures, meta tags, and content across their own sites or others. By extracting header metadata at scale, they can benchmark SEO performance, identify gaps in meta descriptions or Open Graph tags, and conduct backlink profile research, all through an automated, API-driven process.
Overview
About LLMWise
LLMWise is an innovative API solution designed to simplify the complexities of working with multiple AI language models. In a landscape where businesses often juggle various AI providers, LLMWise streamlines this process by offering access to every major large language model (LLM) through a single API. Key players like OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek are all accessible via intelligent routing that optimally matches each prompt to the most suitable model. Whether you need coding assistance, creative writing, or translations, LLMWise ensures that you leverage the best AI for each task. This solution is particularly beneficial for developers and businesses looking to enhance their applications without incurring the overhead of managing multiple subscriptions or API keys. The platform provides robust features like model comparison, blending outputs for superior results, and automatic failover to backup models, ensuring your applications remain resilient and reliable. With LLMWise, you can focus on innovation while reducing costs and complexity.
About WebPageSnap - Professional Web Scraper API
WebPageSnap is a sophisticated, enterprise-grade API engineered to transform the complex task of web data extraction into a simple, reliable, and high-performance service. At its core, it functions as a powerful conduit between the vast, unstructured data of the public web and the structured, actionable information required by modern applications and analyses. By providing a single RESTful endpoint, it abstracts away the technical hurdles of proxy management, browser simulation, and rate limiting, delivering clean HTML or parsed JSON data directly to your workflow. This tool is indispensable for developers building data-driven applications, data scientists aggregating research datasets, marketers conducting real-time competitive analysis, and businesses automating price monitoring or lead generation. Its primary value proposition lies in its architectural excellence: leveraging over 200 global Cloudflare edge nodes, it ensures sub-50ms response times and a 95%+ cache hit rate with a 7-day TTL. This combination of speed, reliability, and intelligence allows users to shift their focus from the mechanics of data retrieval to the insights and value derived from the data itself, making WebPageSnap a critical infrastructure component for any operation reliant on live web information.
Frequently Asked Questions
LLMWise FAQ
How does LLMWise handle model failures?
LLMWise features a circuit-breaker failover system that automatically reroutes requests to backup models when a primary provider is down. This ensures that your applications remain operational without interruption.
Can I use my existing API keys with LLMWise?
Yes, LLMWise supports the "Bring Your Own Keys" (BYOK) feature, allowing users to integrate their existing API keys at provider prices. This flexibility helps reduce costs and streamlines the transition to LLMWise.
Is there a subscription fee for using LLMWise?
LLMWise operates on a pay-per-use model without any subscription fees. Users start with 20 free credits and can utilize additional functionalities based on their usage, making it cost-effective.
How can I compare outputs from different models?
The compare and blend feature in LLMWise allows users to run the same prompt across different models and view their responses side-by-side. This helps identify the best model for specific tasks and improves overall output quality.
WebPageSnap - Professional Web Scraper API FAQ
What is a web scraper API and how does WebPageSnap differ?
A web scraper API is a service that programmatically extracts content from websites, handling the complexities of HTTP requests, parsing, and session management. WebPageSnap distinguishes itself through its enterprise-grade infrastructure. It's not just a simple fetcher; it's built on a global edge network with intelligent caching, realistic browser simulation to bypass anti-bot measures, and automatic JavaScript rendering. This combination ensures high reliability, exceptional speed, and successful data extraction from modern, dynamic websites where other tools may fail.
How does the API handle JavaScript-heavy pages and redirects?
WebPageSnap employs a "Smart Redirect" feature with realistic browser simulation. When a request is made to a page that uses JavaScript to redirect (common in SPAs or tracking links), the API automatically executes the JavaScript in a headless environment, follows all redirects, and returns the content from the final, rendered destination URL. This process is seamless to the user, who receives the complete HTML or JSON data from the ultimate page as if they had navigated there in a real browser.
Is there a free tier available?
Yes, WebPageSnap offers a generous free tier designed for development, testing, and low-volume projects. This tier provides up to 100,000 requests per day at no cost, allowing individuals and small teams to evaluate the API's capabilities and integrate it into their applications without an initial financial commitment. This makes advanced web scraping infrastructure accessible to a broad audience.
What output formats are supported and what is included in the JSON response?
The API supports two primary output formats: html and json. The HTML format returns the raw source code of the final page. The JSON format (which is the default) provides a structured response containing a success flag, the requested and final URLs, and two key objects: header and body. The header object contains parsed metadata like title, description, author, charset, viewport, and all major Open Graph and Twitter Card properties. The body contains the full HTML content of the page, offering the best of both structured data and raw material.
Alternatives
LLMWise Alternatives
LLMWise is a versatile API designed to streamline access to various large language models (LLMs) from leading providers. By offering a single interface to access multiple AI models like GPT, Claude, and Gemini, LLMWise simplifies the process for developers, enabling them to utilize the best model for each specific task without the hassle of managing multiple accounts or subscriptions. Users often seek alternatives to LLMWise due to factors such as pricing structures, specific feature sets, or unique platform needs that may not be fully addressed by this API. When choosing an alternative, it’s important to consider aspects like ease of integration, support for various models, flexibility in pricing, and the ability to optimize performance based on specific use cases, ensuring that the alternative meets both technical requirements and business objectives.
WebPageSnap - Professional Web Scraper API Alternatives
WebPageSnap - Professional Web Scraper API is a specialized tool in the tech tools category, designed for high-speed, reliable extraction of web data. It serves developers and businesses needing to automate the collection of structured information from public web pages with minimal latency. Users often explore alternatives for various reasons. These can include budget constraints, as pricing models vary significantly across providers. Specific feature requirements, such as the need for different data output formats, proxy management, or handling of JavaScript-heavy sites, also drive the search. Furthermore, integration capabilities with existing tech stacks and the scale of operations are critical factors that lead teams to evaluate other options. When selecting an alternative, it's crucial to assess several key aspects. Performance and reliability, measured by uptime and request speed, are paramount. The flexibility of the API, including its ability to return data in usable formats and handle anti-bot measures, is another major consideration. Finally, transparent pricing, clear documentation, and the quality of developer support form the foundation of a sustainable and effective web scraping solution.