Agent to Agent Testing Platform vs LLMWise
Side-by-side comparison to help you choose the right AI tool.
Agent to Agent Testing Platform
TestMu AI validates AI agents for bias, toxicity, and reliability across all interaction modes.
Last updated: February 28, 2026
LLMWise
LLMWise offers a single API to seamlessly access and compare multiple AI models, charging only for what you use.
Last updated: February 28, 2026
Visual Comparison
Agent to Agent Testing Platform
LLMWise
Feature Comparison
Agent to Agent Testing Platform
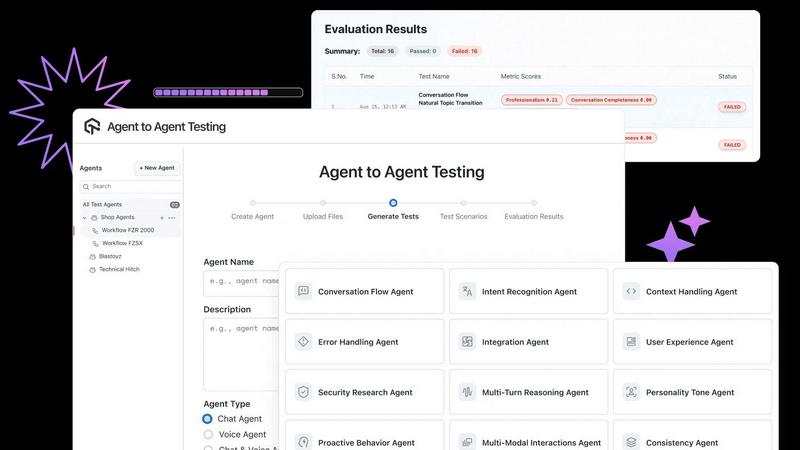
Autonomous Multi-Agent Test Generation
The platform deploys a suite of over 17 specialized AI agents, each designed to probe different aspects of the Agent Under Test (AUT). These include agents focused on personality tone, data privacy, intent recognition, and more. This multi-agent system autonomously generates diverse, complex test scenarios that simulate real human conversation patterns, uncovering edge cases and interaction failures that manual or scripted testing would inevitably miss, ensuring comprehensive behavioral validation.
True Multi-Modal Understanding and Testing
Going far beyond text-based analysis, this feature allows testers to define requirements using diverse inputs such as images, audio files, and video. By uploading PRDs or directly specifying multi-modal prompts, teams can gauge how their AI agent processes and responds to real-world, mixed-media inputs. This ensures the agent's performance is robust across all interaction types it is designed to handle, mirroring actual user environments.
Diverse Persona-Based Synthetic User Testing
To test like real humans, the platform enables simulations using a wide variety of predefined and custom user personas, such as an "International Caller" or a "Digital Novice." Each persona exhibits different behaviors, needs, and interaction styles. This diversity ensures the AI agent is evaluated for effectiveness and empathy across the entire spectrum of its intended user base, highlighting potential biases or performance drops with specific demographics.
Integrated Regression Testing with Risk Scoring
The platform facilitates end-to-end regression testing for AI agents with intelligent risk scoring. After changes or updates, it automatically re-runs test suites and provides a detailed risk assessment, highlighting potential areas of concern. This allows teams to prioritize critical issues, optimize testing efforts, and maintain a high standard of quality and reliability throughout the agent's development lifecycle with clear, actionable insights.
LLMWise
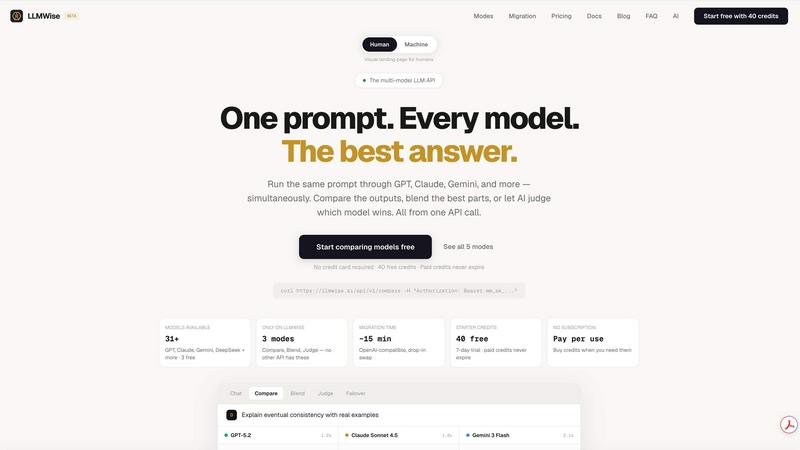
Smart Routing
LLMWise employs advanced smart routing to ensure that every prompt is directed to the most appropriate model. For instance, coding queries can be sent to GPT, while creative tasks are routed to Claude, and translations are handled by Gemini. This feature maximizes efficiency and output quality by leveraging the strengths of each model.
Compare & Blend
The compare and blend feature allows users to run prompts across different models side-by-side, enabling direct comparison of responses. Users can blend outputs from multiple models into a single, cohesive answer, enhancing the overall quality of the results. Additionally, the Judge mode evaluates outputs to determine which model provides the best response.
Resilient Failover
LLMWise is built with resilience in mind, featuring a circuit-breaker failover system that automatically reroutes requests to backup models if a primary provider experiences downtime. This ensures that applications remain operational and reliable, protecting users against interruptions.
Test & Optimize
Developers can utilize LLMWise's comprehensive benchmarking suites and batch tests to optimize performance based on speed, cost, or reliability. Automated regression checks are also included to ensure that updates do not introduce new issues, enabling continuous improvement of AI integrations.
Use Cases
Agent to Agent Testing Platform
Pre-Production Validation for Customer Service Chatbots
Before launching a new customer support chatbot, enterprises can use the platform to simulate thousands of customer inquiries, from simple FAQ retrieval to complex, multi-issue troubleshooting. This validates the agent's accuracy, escalation logic, policy adherence, and tone, ensuring it reduces live agent handoffs and maintains brand professionalism before interacting with real customers.
Compliance and Safety Auditing for Financial Voice Assistants
Banks and fintech companies deploying voice-activated assistants for balance inquiries or transactions require stringent compliance checks. The platform tests for data privacy violations, hallucination of financial data, and appropriate security escalation protocols. It autonomously probes for toxic or biased responses under stress, ensuring the agent meets strict regulatory and ethical standards.
Scalable Performance Benchmarking for Sales AI Agents
Sales teams implementing AI agents for lead qualification can benchmark performance at scale. The platform uses diverse buyer personas to test the agent's ability to recognize purchase intent, handle objections, and provide accurate product information across countless simulated conversations, providing metrics on effectiveness and conversion pathway reliability.
Continuous Monitoring and Improvement of Healthcare Assistants
For healthcare providers using AI for patient intake or symptom triage, consistent and accurate performance is critical. The platform enables continuous regression testing after every model update, checking for hallucinations in medical advice, maintaining empathy in tone, and ensuring correct handoff to human professionals, thereby mitigating risk and improving patient trust over time.
LLMWise
Application Development
LLMWise is ideal for application developers who require various AI functionalities without managing multiple subscriptions. By leveraging a single API, developers can integrate diverse LLM capabilities into their applications, enhancing user experiences with tailored responses.
Content Creation
For content creators, LLMWise offers a powerful tool to generate high-quality written material. Whether writing blogs, social media posts, or marketing copy, users can utilize different models to refine their content, ensuring creativity and accuracy.
Translation Services
Businesses that require translation services can benefit from LLMWise's intelligent routing to the best translation models. This feature ensures that translations are not only accurate but also contextually appropriate, enhancing communication across languages.
Research and Analysis
Researchers can utilize LLMWise to gather insights and synthesize information from multiple models. The ability to compare and blend responses allows for a more comprehensive analysis, leading to better-informed conclusions and recommendations.
Overview
About Agent to Agent Testing Platform
Agent to Agent Testing Platform represents a paradigm shift in quality assurance, engineered specifically for the unpredictable and autonomous nature of modern AI agents. As enterprises rapidly deploy conversational AI across chatbots, voice assistants, and phone-calling agents, traditional testing frameworks—designed for deterministic, static software—fail to capture the dynamic, multi-turn complexities of agentic systems. This platform is the first AI-native quality and assurance framework built to close that critical gap. It provides a unified environment to rigorously validate AI behavior before production, simulating thousands of real-world user interactions across chat, voice, and multimodal channels. By moving beyond simple prompt checks to evaluate full conversational flows, it empowers development and QA teams to proactively uncover long-tail failures, edge cases, and subtle interaction flaws. The core value proposition lies in its autonomous, multi-agent testing approach, which leverages over 17 specialized AI agents to generate tests, assess key metrics like bias, toxicity, and hallucination, and ensure reliability, safety, and policy compliance at scale. It is designed for organizations that rely on AI for customer service, sales, support, and other mission-critical interactions, offering them the confidence that their AI agents will perform as intended for every user.
About LLMWise
LLMWise is an innovative API solution designed to simplify the complexities of working with multiple AI language models. In a landscape where businesses often juggle various AI providers, LLMWise streamlines this process by offering access to every major large language model (LLM) through a single API. Key players like OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek are all accessible via intelligent routing that optimally matches each prompt to the most suitable model. Whether you need coding assistance, creative writing, or translations, LLMWise ensures that you leverage the best AI for each task. This solution is particularly beneficial for developers and businesses looking to enhance their applications without incurring the overhead of managing multiple subscriptions or API keys. The platform provides robust features like model comparison, blending outputs for superior results, and automatic failover to backup models, ensuring your applications remain resilient and reliable. With LLMWise, you can focus on innovation while reducing costs and complexity.
Frequently Asked Questions
Agent to Agent Testing Platform FAQ
What makes Agent-to-Agent Testing different from traditional QA?
Traditional QA is built for deterministic software with predictable inputs and outputs. AI agents, however, are probabilistic and engage in dynamic, multi-turn conversations. Agent-to-Agent Testing is a native framework designed for this complexity. It uses other AI agents to generate and evaluate full conversational flows across modalities, testing for emergent behaviors, reasoning flaws, and real-world interaction patterns that scripted tests cannot replicate.
What key metrics does the platform evaluate for an AI agent?
The platform provides deep, actionable evaluation across a plethora of key AI performance and safety metrics. This includes assessing the agent for bias and toxicity in its responses, identifying hallucinations (fabricated information), and measuring effectiveness, accuracy, empathy, and professionalism. It also validates specific functional logic like escalation protocols and data privacy compliance.
Can I test voice and phone-calling agents, or is it only for chatbots?
Absolutely. The platform is built for true multi-modal testing. It supports the validation of AI agents across all major interaction channels: text-based chat, voice assistants, and inbound/outbound phone-calling agents. You can define test scenarios that simulate authentic voice or hybrid interactions, ensuring your agent performs reliably regardless of how the user communicates.
How does the platform handle test scenario creation?
The platform offers two powerful approaches. First, it provides autonomous test generation where its library of specialized AI agents creates diverse, production-like scenarios. Second, it allows teams to access a library of hundreds of pre-built scenarios or create completely custom scenarios tailored to specific business needs and user journeys, offering both flexibility and comprehensive coverage.
LLMWise FAQ
How does LLMWise handle model failures?
LLMWise features a circuit-breaker failover system that automatically reroutes requests to backup models when a primary provider is down. This ensures that your applications remain operational without interruption.
Can I use my existing API keys with LLMWise?
Yes, LLMWise supports the "Bring Your Own Keys" (BYOK) feature, allowing users to integrate their existing API keys at provider prices. This flexibility helps reduce costs and streamlines the transition to LLMWise.
Is there a subscription fee for using LLMWise?
LLMWise operates on a pay-per-use model without any subscription fees. Users start with 20 free credits and can utilize additional functionalities based on their usage, making it cost-effective.
How can I compare outputs from different models?
The compare and blend feature in LLMWise allows users to run the same prompt across different models and view their responses side-by-side. This helps identify the best model for specific tasks and improves overall output quality.
Alternatives
Agent to Agent Testing Platform Alternatives
Agent to Agent Testing Platform is a specialized AI-native quality assurance framework designed for validating the behavior of autonomous AI agents. It belongs to the AI Assistants and agentic systems testing category, focusing on multi-turn, multimodal interactions that traditional software QA tools cannot adequately assess. Users often explore alternatives for various reasons, including budget constraints, the need for different feature sets like integration with specific development environments, or requirements for a more general-purpose testing solution that covers non-agentic software as well. Some may seek platforms with different pricing models or those that focus on a narrower aspect of testing, such as only chat-based interfaces. When evaluating an alternative, key considerations should include the platform's ability to simulate complex, real-world user interactions across your required channels (voice, chat, etc.), its methodology for generating edge-case tests, and the depth of its validation for security, compliance, and operational logic. The ideal solution should provide scalable, automated testing that mirrors production complexity to ensure agent reliability and safety before deployment.
LLMWise Alternatives
LLMWise is a versatile API designed to streamline access to various large language models (LLMs) from leading providers. By offering a single interface to access multiple AI models like GPT, Claude, and Gemini, LLMWise simplifies the process for developers, enabling them to utilize the best model for each specific task without the hassle of managing multiple accounts or subscriptions. Users often seek alternatives to LLMWise due to factors such as pricing structures, specific feature sets, or unique platform needs that may not be fully addressed by this API. When choosing an alternative, it’s important to consider aspects like ease of integration, support for various models, flexibility in pricing, and the ability to optimize performance based on specific use cases, ensuring that the alternative meets both technical requirements and business objectives.