Friendli Engine
About Friendli Engine
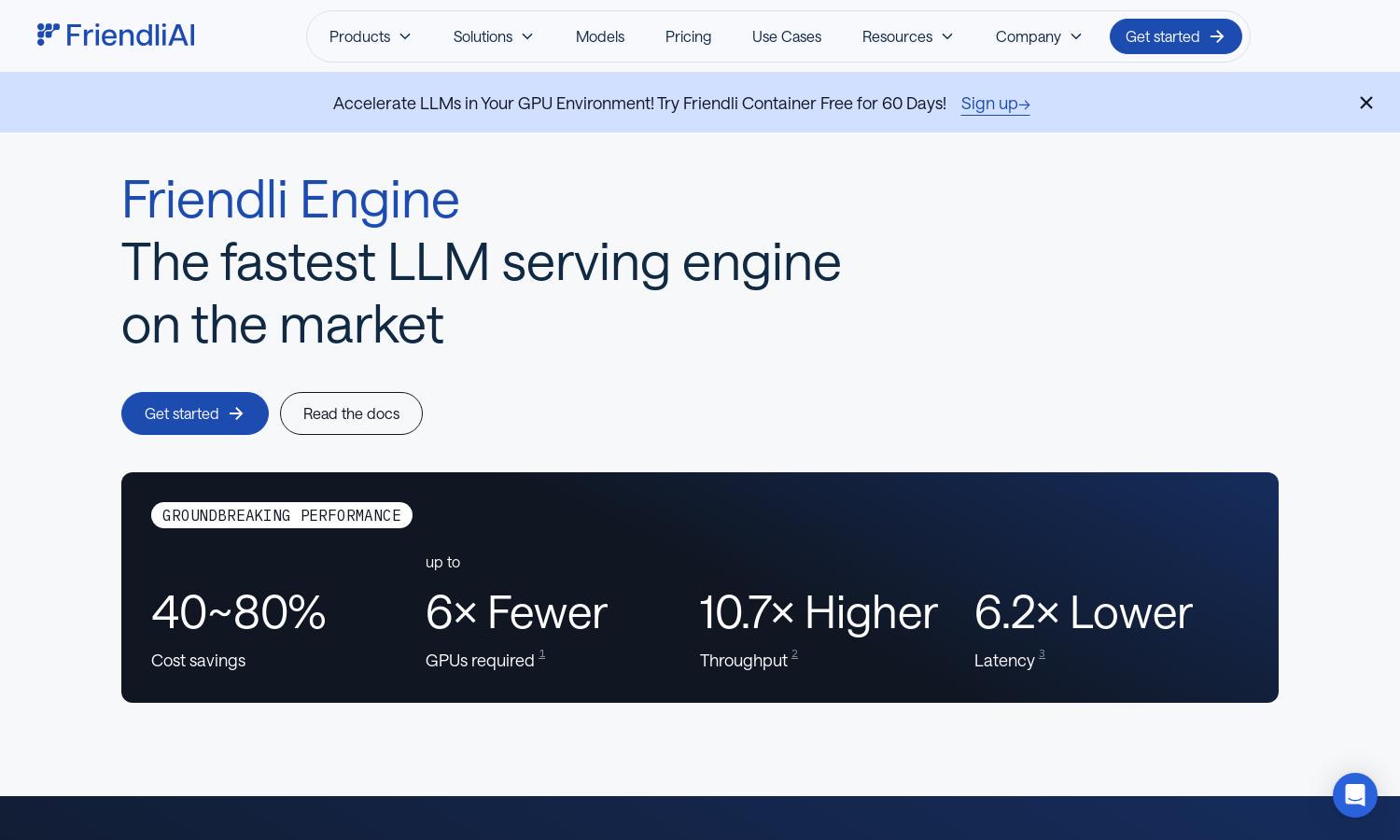
Friendli Engine revolutionizes LLM deployment by optimizing inference speeds and costs for generative AI. With unique features like iteration batching, users enjoy remarkable throughput improvements, making their LLM model serving efficient and accessible. It's designed for businesses looking to leverage high-performance AI solutions seamlessly.
Friendli Engine offers various pricing plans tailored to different user needs. Each tier provides comprehensive features for LLM inference, including cost-effective access to optimized GPU resources. Upgrading unlocks additional capabilities and savings, catering to individuals and organizations aiming for enhanced generative AI performance.
Friendli Engine features a user-friendly interface designed for intuitive navigation and efficient model management. Its streamlined layout ensures a seamless browsing experience, with easy access to advanced optimizations and tools, empowering users to deploy and fine-tune LLMs with confidence and minimal friction.
How Friendli Engine works
Users begin by onboarding on Friendli Engine, where they create or import their LLM models. The platform's intuitive dashboard allows for easy navigation through features like batch processing and model settings. With tools for optimization like speculative decoding and TCache, users can efficiently manage resources and achieve faster inference times, all while monitoring performance metrics.
Key Features for Friendli Engine
Iteration Batching
Friendli Engine's iteration batching technology enables concurrent generation requests management, significantly boosting throughput. This innovative solution allows users to achieve up to tens of times faster LLM inference, ensuring efficiency and reduced costs, making Friendli Engine a standout choice for generative AI performance.
Multi-LoRA Model Support
Friendli Engine offers impressive capabilities for serving multiple LoRA models on a single GPU, streamlining the customization process for LLMs. This feature enhances operational efficiency by reducing the need for extensive GPU resources, providing users with an accessible and cost-effective solution for diverse AI applications.
Speculative Decoding
The speculative decoding feature of Friendli Engine allows for rapid LLM inference by making educated guesses on future tokens. This optimization not only accelerates output but also ensures accuracy, helping users obtain high-quality results faster, thus enhancing the overall performance of generative AI models.
You may also like:








